I’ve been tinkering with Elixir and Phoenix a bit recently. I really like the language (it’s the first time since Ruby that a new (to me) language has seemed this much fun) and Phoenix seems like a rock solid framework, but I was interested in what the surrounding ecosystem was like compared to the much more mature Ruby/Rails landscape. This was just a tyre-kicking exercise – I only really took each tool as far as making sure I could install it and do the basics. Incidentally, a great place to find popular Elixir resources is Awesome Elixir.
The app I started creating (which does virtually nothing!) is on github, and here are some brief notes of the stuff I tried out:
White Bread (because that’s what you make cucumber sandwiches with) is a Gherkin parser/runner. It works in much the same way as Cucumber.
It took me a bit of fiddling to get it working with Phoenix, but nothing too difficult. According to the docs it should generate a sample context (equivalent to a Cucumber step definitions file) when you first run it, but that failed. Once I’d copied the example from the docs though, it worked fine.
The most obvious difference in the steps is that they operate (as you would expect) in a functional style, passing the context from one step to the next rather than relying on shared state. This is actually quite nice, as it makes it very clear what data is being passed between steps.
First I tried TucoTuco (apparently it’s an animal similar to a capybara). The first problem I had was that Webdriver (a dependency) failed to compile under Elixir 2.2, so I had to drop back to Elixir 1.1.1 (I raise an issue against the project, and got a quick reply saying it’ll be fixed soon). I also had to explicitly add ibrowse as a dix dependency, as it seems to only be available from GitHub, not hex. I found TucoTuco’s documentation to be a bit sketchy, and never quite got it working with Phoenix.
Switching to Hound, I found the documentation to be much better. It still uses webdriver, so had the same compatibility issue as TucoTuco, but not ibrowse.
One difference compared with Capybara is that you need to manually start phantomjs (phantomjs --wd), rather than it being started for you. It should be easy enough to wrap it in an Elixir application, but I haven’t tried that yet.
Previously I’d just been using the latest version of Elixir from Homebrew, but having to downgrade because of the webdriver incompatibility set me looking for a version manager. Exenv follows the philosophy of rbenv rather than rvm, is dead simple to install and use, and just keeps out of your way and works flawlessly.
The docs a bit out of date, but otherwise works more-or-less as expected, failing the build if the rules you specify are broken. I suspect it doesn’t have quite the range of rules or configurability as rubocop (yet).
If you just want gentle style suggestions rather than enforcement, consider Credo instead (which I didn’t try).
Coverage is built into exunit and espec, using Erlang’s cover tool:
mix espec --cover
The output’s not great though, so enter Coverex, which produces output much more like simplecov’s.
Unfortunately both tools seem to mark things like use statements within defmodule blocks as uncovered, which leads to misleadingly low coverage scores. I can’t see any obvious way to have it fail the build on low coverage either. In ruby I normally fail if any line is uncovered (if you’re test-driving the code, that’s never going to happen, right?), so that’s two reasons I can’t do the same thing in Elixir.
In the unlikely event that anyone wants to scroll through the whole history of the TDD demo Rails app I did the other day, I wrote a little script to munge it all into one page. And here it is.
It runs through the git history of a project, printing the full message for each commit, followed by a complete listing of each changed file, with added, removed or changed lines highlighted. It then outputs the result into a big ugly HTML file. Like this.
I decided to do a clean install on my new [work] Mac, rather than just copying everything across from my old one. I thought I’d note down some of the things I installed, in case it comes in handy for anyone else (particularly new Mac users).
I’ve mostly ignored common cross-platform stuff like DropBox, 1Password etc, and setting up things like git and ruby. If you just want to quickly set up a Mac for ruby development, Thoughtbot’s laptop project (or Adam’s fork) might be the way to go.
If you’ve got any other can’t-live-without Mac apps that I might have missed, let me know!
Today I wanted to edit a big chunk of text (the source of a wiki page) in a browser textarea, and remembered that I used to have an app that let me open any text in vim, then paste the result back where it came from. Eventually I found the app I was thinking of – QuickCursor – but it turns out it’s no longer available.
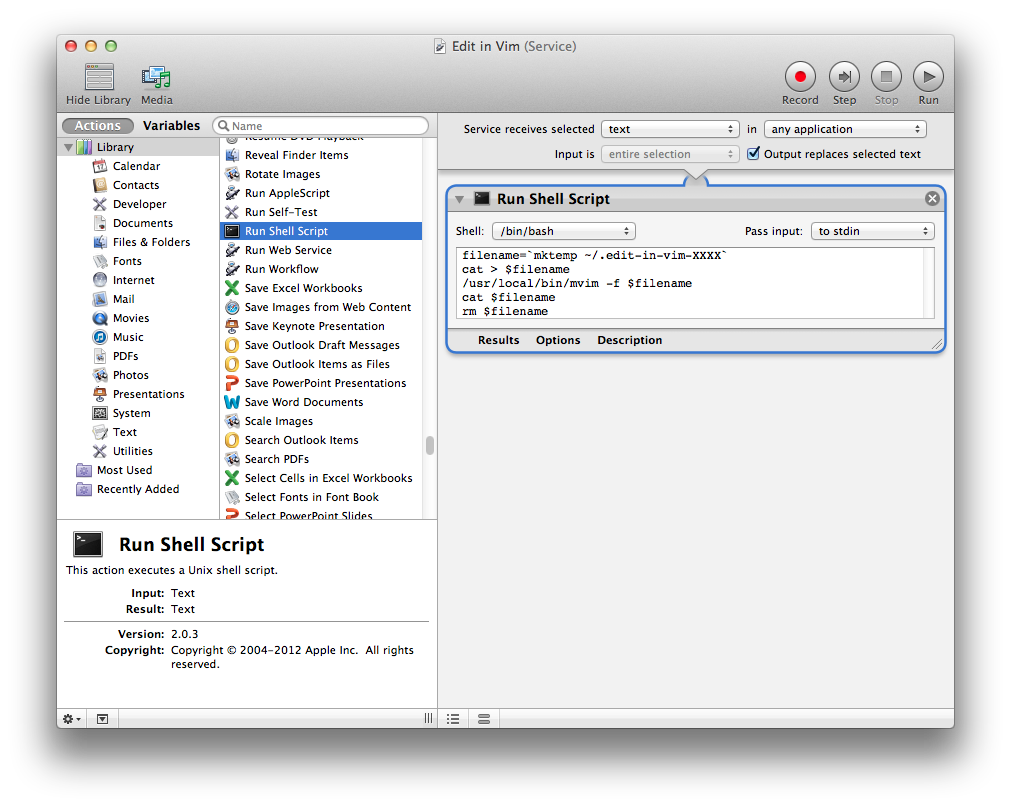
Coincidentally I was looking into how to do something else tonight, and the answer was to create a service that ran an AppleScript, and it occurred to me that I could probably make a basic “edit in vim” service fairly easily. Turns out I was right…
Open the “Automator” app, and create a new service. Add a shell script action, and paste in the following script (this assumes you’ve installed the mvim script that comes with MacVim):
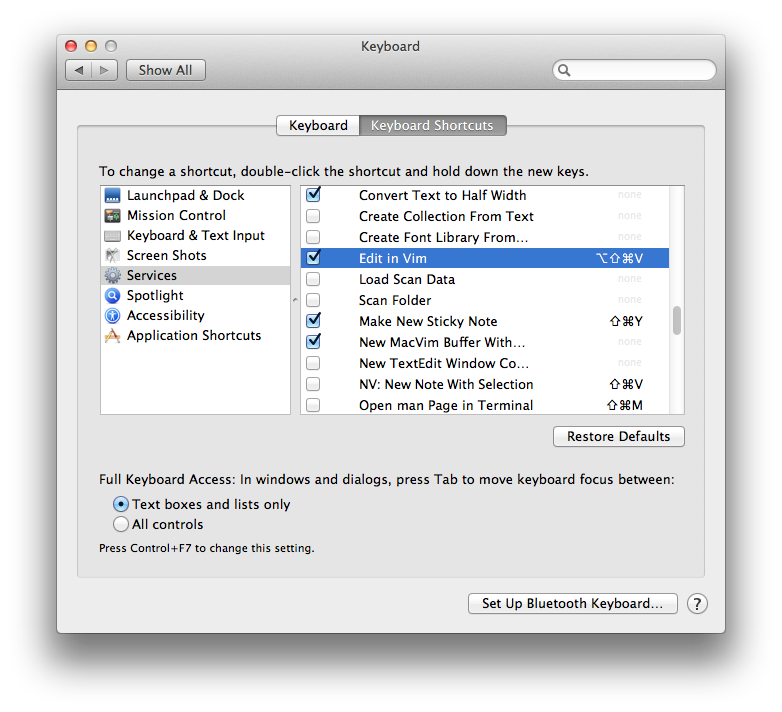
Select “Output replaces selected text” in Automator, save the service, and you’re done. Just select some text (it doesn’t select-all for you like QuickCursor did), right-click and run your new service. You can also assign a keyboard shortcut in System Preferences:
At last night’s FESuffolk meeting I gave a lightning talk on getting started with unit-testing Javascript/coffeescript using jasmine-headless-webkit. I made a screen recording, so if you missed it you can still experience my frantic babbling (I had Keynote set to auto-advance, using the Ignite 20 × 15 second slide format, and as usual I tried to cram too much into each slide).
This one had Adam and me stumped for a while. Trying to check that a method is only called on objects that respond to it:
describe "Foo#call_all_the_things" do
let(:foo_1) { stub :foo_1, bar: "hello" }
let(:foo_2) { stub :foo_2 }
subject { Foo.new foo_1, foo_2 }
it "only calls bar on objects that respond to it" do
foo_1.should_receive :bar
foo_2.should_not_receive :bar
subject.call_all_the_things(:bar)
end
end
class Foo
def initialize *things
@things = things
end
def call_all_the_things method
@things.each do |thing|
thing.send method if thing.respond_to? method
end
end
end
1) Foo#call_all_the_things only calls bar on objects that respond to it
Failure/Error: thing.send method if thing.respond_to? method
(Stub :foo_2).bar(no args)
expected: 0 times
received: 1 time
Hmm. Why is it calling bar on the thing that doesn’t respond to it? Perhaps rSpec doubles don’t handle respond_to? properly?
Of course! To do the should_not_receive check, it needs to stub the method, which means it responds to it!
Two possible solutions: either let the fact that the missing method isn’t called be tested implicitly, or specify that when objects that don’t respond to the method exist, no NoMethodError is raised.
Ever since attending code retreat at Bletchley Park (the UK leg of Corey Haines’s code retreat tour) last year, I’d been vaguely intending to try and run an internal one at work. I finally got round to it this month, when a few people expressed an interest in a code retreat as a one-off alternative to the usual developer conferences we run a couple of times a year. I thought I’d share my experiences facilitating a code retreat for the first time, in case it’s helpful to anyone thinking of doing the same.
Beforehand
The “official” code retreat site has some good information on things to consider when hosting and facilitating. I suspect organising an internal company event is easier than a public one, because hopefully you’ll have a venue available and you won’t need to worry about sponsorship. The only one of Corey’s rules I ignored was the one about giving people decent food at lunchtime, but we did at least manage to beg enough budget (thanks Mel!) to be able to provide cheap Tesco sandwiches at lunchtime and a few random snacks and coffee during the day. I don’t feel too bad because rather than asking people to “come out at eight in the morning to spend the day coding”, we were giving them an excuse to spend a work day away from their projects, getting paid to practice.
We also planned to start at nine o’clock rather than the traditional eight. I think for public events the early start, usually on a Saturday, is a good way of selecting only people who really want to take part, but running it at work I wanted to swing the balance a bit towards encouraging people to come (I work on a large site with probably a couple of hundred developers scattered amongst the 3000-odd BT people, and part of the motivation for running this kind of event is to try and put developers from different teams in touch with each other).
With a bit of publicity via mailing lists and posters on site, 27 people had signed up. That seemed like about the right number, although I had no idea how many of those would turn up, or whether anyone would turn up without registering. I turned up at the office in plenty of time, and was lucky enough to get some last-minute tips from the master:
Getting started
As it turned out we had a few glitches to deal with before we could get going – firstly the venue was locked and we only managed to get in because Rupert knew how to find the secret back entrance, then Adam and Anna got kicked out of Tesco for a fire alarm while buying the food – so we ended up starting at closer to 9.30.
Potentially the biggest disaster though was that the hopper was missing from the coffee machine (most likely locked away to stop people like us using it with our own beans instead of paying for catering). Fortunately it takes more than a little detail like that to defeat a room full of engineers, and we soon had a workaround in place using a plastic cup with the bottom cut out.
Once the caffeine supply was assured and we were finally ready to start, I gave a quick presentation covering the purpose of the day, the four rules of simple design and Conway’s game of life:
With everyone hopefully having a reasonable idea of what was going on, people paired up and started the first session. There were about 25–30 people (I forgot to count), split something like 70:20:10 between Java, Ruby and Groovy. In the first session, as expected, everyone was mostly just getting a feel for the problem, and realising that it’s not quite as simple as it appears from the list of rules.
After 45 minutes, I put on my best exam invigilator voice and got everyone to stop typing, delete their code and gather round. Pairs were split roughly evenly between those that started with a grid and those that started with a cell, and we had a short discussion about how a grid approach using a two-dimensional array fitted in with the “infinite grid” constraint. Some of those who had started from a cell were thinking about approaches for allowing cells to know about their neighbours, but no-one had got that far yet.
Mixing it up
For the second session, I suggested that those that had started with a grid tried starting from a cell instead, and vice versa. There were also quite a few people who wanted a chance to try Ruby, so they tried to grab the rubyists before anyone else did. Little did they know that they would find themselves exposed to Vim (and in some cases Mac OS X) at the same time, but that’s just a bonus.
In general people who tried both seemed to prefer the cell approach, partly because it made it easier to test-drive the rules. With a grid, people found they were having to implement some kind of to_string or render method to allow the transformed grid to be compared with the expected result. The biggest puzzle with the cell approach was how to handle the relationship between multiple cells.
I introduced a list of possible constraints people might want to consider to make things more interesting:
No if statements (or other conditionals).
No loops.
No methods longer than five lines (or four, or three…)
No more than three methods per class.
No ‘naked’ language primitives.
No built-in data structures.
I also attempted to explain TDD as if you meant it, in case anyone fancied giving it a go. Unfortunately my description was rather garbled, not helped by the fact that I’m not sure I fully understand it myself (I’m still annoyed that I picked the wrong track at SC2009 and missed Keith’s original presentation of the exercise, and it turns out Adam made the same mistake at SPA2010).
Session three
By the third session several pairs were starting to experiment with storing cell objects either in a set (with each cell knowing its position) or a hash, keyed by position. Some people used a comma-separated “x,y” string as the key, but with a bit of prodding most ended up replacing it with a point class of some kind.
One pair decided to start with a single cell, then initialise other cells with their neighbours. This initially seemed promising, but soon led to complications with circular references, as well as the need to keep dead cells around to maintain a connection between cells with space between them.
Another pair started developing the rules with a cell class, and initially had an alive? method which performed the life calculation. After some discussion they split the class into two – one for a living cell and another for a dead one. This removed a level of nesting from the calculations (which ended up in a different method), but interestingly left alive? in both classes, hardcoded to true and false respectively. We decided that this would have looked less odd in Java, where the method would have been declared abstractly in a superclass or interface.
One pair had decided to try implementing a solution with no if statements, but resorted to cheating by using a case instead!
In general, a lot of people – particularly those new to TDD – were starting to get frustrated, feeling like they were just getting to the point where they were “about to start the interesting bit” as the 45 minutes were up. I told them that we’d just have two sessions after lunch rather than three, with the second session lengthened to give people a chance of implementing a working game.
Fourth – and as it turned out final – session
After lunch we started the fourth session, but it soon became clear that several pairs had already decided to abandon TDD and clean code in favour of trying to solve the problem. I completely understand how they felt – I wasted most of the sessions at the code retreat I attended simply pushing for the finish line instead of letting it go and concentrating on perfecting the internal quality of the code – but it seemed like we’d lost sight of the key goal of the day a little. I suspect I’m mostly to blame for that, and I’m sure a more experienced facilitator could have done a better job of gently guiding people in the right direction. Anyway, it seemed sensible to bow to the inevitable, let everyone carry on for another 45 minutes and wrap up a bit earlier than planned.
With the extra time, a few pairs did manage to get a working implementation, but the prize for the most impressive (cancelled out by a booby prize for abandoning TDD and neglecting the quality of their code!) goes to Jon and Jia Yan, who produced an SWT app that allowed graphical editing of the grid, variable speed and saving and loading files. They used the “set of live cells” approach, with an effectively infinite grid. Resizing the window on screen allowed you to show or hide cells, but the ones off the edge of the visible area continued to multiply.
Matthew and Rupert decided to look at someone else’s solution in Clojure, to understand how a functional approach using list comprehensions can lead to a very concise solution. They also played around with a Ruby version using the same techniques. Looking at the Clojure code led to a slightly rearranged version of the rules for life at a particular location after a clock tick:
Cells which had three neighbours are alive
Cells which had two neighbours are unchanged
All other cells are dead
Paul, stuck on his own after his pair got dragged off onto a conference call (the perils of being a senior manager!), had a play with TDD as if you meant it. I think by the end of the session he was starting to get somewhere. Further than me, at any rate.
Wrapping it all up
After letting Jon show off a glider gun running in their SWT universe, we gathered round for the closing circle, asking everyone what they’d learned, what had surprised them, and what they’d do differently back at work on Monday as a result. Probably the most common comments revolved around the fact that neither of the two most obvious solutions turned out to be the best, suggesting that it’s worth spiking a few alternative approaches before heading blindly off down what may be a blind alley. Quite a few people were new to pairing, TDD or both, and generally seemed to agree that both provided benefits, although a couple of people felt that TDD was making things take much longer. Reassuringly, of the pairs that had abandoned TDD to concentrate on trying to get a working solution, most had found themselves descending into confusion without the tests to guide them.
Final thoughts
Overall, the event seemed to be a success. For quite a few people this was their first experience of TDD, and the opportunity to get first-hand experience by pairing with someone more experienced seemed to be useful. I was particularly pleased to see someone who’s recently come back into software development after a long time away doing a great job of holding his pair back from rushing into implementation without a failing test.
On a less positive note, I didn’t feel we really concentrated enough on “perfect” code and the four rules of simple design. I know from experience that it’s hard to let go of the natural desire to try and finish solving the problem, and I felt that a lot of people were getting frustrated enough without me peering over their shoulders picking holes in their code (however nicely I tried to do it). Perhaps this is a case of horses for courses, with the concentration on design perfection more suitable for a different mix of participants, or perhaps it just reflects my lack of experience facilitating this kind of event.
Also, I don’t think we really had enough sessions for the code retreat magic to start kicking in properly. We’d planned to have the recommended five or six, but a combination of the late start and a general loss of direction after lunch reduced that to four (with the fourth being double-length).
The important thing, of course, is that people learned something by participating, and I hope that was the case. Maybe we’ll do another one one day, and use the experience of this one to make it even better.
[Updated 11 Feb 2011 – I’m not sure the original version actually worked properly.]
Quite often I’ll make small changes to a project’s code which I’m 99% sure won’t break the build. Of course thanks to Murphy’s Law that probability falls to about 10% if I decide to risk it push the changes upstream without running the full build locally.
Now even if the build only takes a few minutes to run, that’s a few minutes which I can’t spend doing anything else with the code, because if I save a file I can’t be sure whether the original or changed version will be used in the tests. What I’d like to be able to do is to run the build in the background, with changes automatically pushed upstream if everything’s green, or an alert shown if either the build fails or the push is rejected (because someone else has pushed a change while the build was running).
Fortunately with a distributed version control system like git, this is fairly easy.
Firstly, clone the local working repository and set up a remote pointing to the clone:
cd ../myproject-staging
# Allow pushing into the checked-out branch
git config receive.denyCurrentBranch ignore
# Create a remote for the upstream server you want to push to (change the URI!)
git remote add upstream git@your.upstream.server/your/repository/path.git
Do anything that needs doing to allow the cloned project to build (if you have a test database, create a separate instance to avoid tests interacting with your main workspace), and verify that the build runs.
This will reset your checked-out working copy to the pushed master, then run .git/hooks/post-reset in the background. Create that file with the following content:
#!/bin/bash
function error {
growlnotify -s -t `basename $PWD` -m "$1"
exit 1
}
# Replace this with your build command
bundle install --local && rake || error "Rake failed"
git push upstream master || error "Git push failed"
growlnotify -s -t `basename $PWD` -m "Built and pushed successfully"
Make sure both these hooks are executable:
chmod u+x .git/hooks/post*-receive
Now, back in your normal working repository you should just be able to type git push staging (add --force if you’ve rebased your normal master and get an error about the push not being a fast-forward), and the project will build in the staging repo. If everything works, it’ll push upstream and you’ll get a Growl notification (assuming you have Growl and growlnotify, or the equivalents for your OS, installed). If it fails, you’ll also get a Growl notification. I’ve made the alerts sticky, so I don’t miss them – if you don’t want that, just remove the -s flag. The build errors will be in the build_output file.
After procrastinating and holding on to the wandering book for much too long, I finally made my entry. You can read it on the site, and here’s the text if you can’t decipher my handwriting:
I work in a large “enterprisey” company where craftsmanship is, unsurprisingly,
not the dominant model of software development. However, a craftsmanship ethos
still exists in some of the remaining pockets of in-house development, and if
anything appears to be strengthening.
For the first few years of my software career, I treated it very much as a day
job. I turned up; I wrote some code (or, for a horrendous proportion of the
time, some documents); I went home. I learned just enough to enable me to
complete whatever I was working on, but no more. I used the tools I was given,
or those I was familiar with, regardless of their suitability for the task at
hand.
Then I started working with someone who was trying cool new stuff. Dependency
injection. Automated testing. Continuous integration. I realised how
out-of-touch I was in my ideas of how software should be developed, and started
trying to put that right. I read about XP and Agile, and started following
blogs and reading articles. I went to XPDay, and turned up at the odd XTC pub
night when I happened be in London on a Tuesday.
More importantly, I started caring about my code. Instead of thousand-line
procedures, I started separating concerns and following OO principles. I wrote
unit tests, and after a while I got the hang of TDD. Month-long manual testing
and bug fixing phases gave way to an automated nightly build and a quick
confidence check, and eventually to something approaching continuous
deployment.
Of course, the more widely I look at what others are doing, the more aware I am
that even when I think I might be doing something reasonably well, there are
always people out there doing it much, much better. I may never approach their
level, but I can learn from their work and thus improve mine. In turn I hope I
can pass something on to others.
So, to finally get to the point, I agree with earlier contributors that
craftsmanship is about caring, learning, practicing and sharing. Underpinning
all this though is community. Not ‘the’ software craftsmanship community, but
the community of other developers you work with; the communities around the
languages and tools you use; the agile, lean and XP communities; the community
of random people you met once at a conference – or maybe have never met at all
– and started following on Twitter.
Without these communities, we become isolated, and may start believing that the
way we currently work is ‘best practice’. We need our fellow professionals to
compare ourselves against and to learn from, otherwise we can lapse into
complacency and let our skills (and our profession) stagnate.