Last Thursday I attended the SC2009 conference at the BBC Media Centre in London. Here are a few notes (assuming I get round to finishing the post – I see I still have an unfinished draft about a session from XPDay2007).
MappingPersonal Practices (Ade Oshineye)
This was a simple exercise where everyone spent five minutes drawing a mind-map of the software development practices they find most important to them, then spent 90 seconds each listing and describing them. The intention was to then go round again and say which practices you’d heard others mention that you wanted to try, but time ran out.
Here’s my selection, converted to Graphviz to save you the pain of trying to decipher my handwriting:
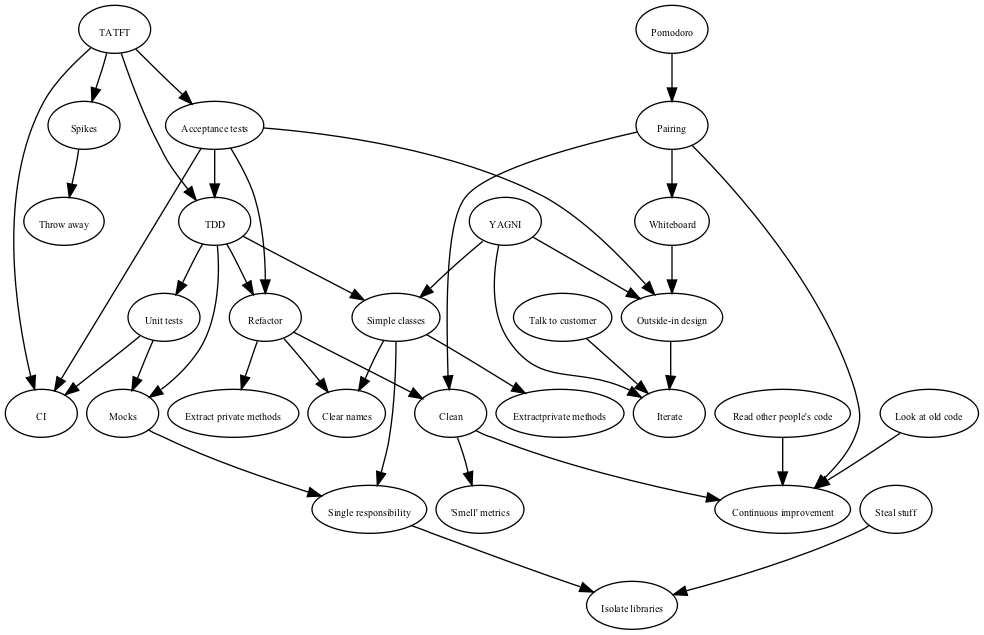
Of the practices mentioned by others, the ones I noted down that I ought to try are speaking at conferences, learning other languages (I haven’t played with a new one for a while), getting feedback from others in the team and reading classic journal papers (conveniently Michael Feathers has just posted a list of recommended ones).
Ruby Kata & Sparring (Micah Martin)
Micah (who had come all the way from Chicago just for this conference!) described the coding kata, linking it to the martial arts practice from which the idea was taken. Trivia fact: the name of Micah’s company, 8th Light, is the literal translation of Hakkoryu, the school of Jujitsu that Micah followed.
He mentioned two different views of katas: Dave Thomas’s suggestion to practice solving the same problem many times and reflect on what you are learning, and Uncle Bob Martin’s approach where you watch a master solve the problem and mimic their process (the latter seems closer to the practice of kata in martial arts). Micah suggested that both of these are missing an important aspect of martial art kata: performance.
Performing a code kata in front of other craftsman gives you a purpose for practicing it. You can receive feedback, learn and address your weaknesses and measure your skill against others, and it shows respect for the craft.
Micah performed a code kata himself, implementing Langston’s Ant in Ruby and asking for a score out of ten at the end (most people gave seven or eight). Finally he mentioned sparring as another technique borrowed from martial arts, and talked about the Battleship tournament which he set up. Apparently this will be repeated soon, using Hangman as the problem to solve.
If you want to see more, there’s a video of Micah making the same presentation at RubyConf 2008, and also a screencast of the Langston’s Ant kata.
Three Paradigms: Taking An Extreme Position on Code Style in a Safe Environment (Keith Braithwaite)
The purpose of this session was to take a piece of contrived “enterprisey” code, make three separate refactorings on it and see what effect they had on the ease of making changes to the code. The refactorings were basically removing conditional logic, removing getters and setters, and making certain classes unmodifiable.
The example code was available in Java and C# (the so-called country-and-western languages – “We got both kinds…”). Unfortunately, like many people there my Java skills were a bit rusty (and my C# skills non-existent), so by the time I’d grabbed the code off one of the memory sticks that were floating round, set up a project in Eclipse, realised that I didn’t have junit.jar and found someone to copy it from, I didn’t really have enough time to complete any of the refactorings. I also spent a while puzzling over what the purpose of the UserDTO class was, as it seemed like it would have been easier to just pass User objects around. Turns out that the point was to show that there was no point (if you see what I mean). Fortunately I seem to have avoided being exposed to the kind of pattern-obsessed enterprise code where these useless nojos are considered good practice. It doesn’t surprise me though – to quote Keith, “Curly bracket languages make you stupid”.
I don’t think anyone got as far as finishing all the refactorings, or making behavioural changes to the resulting code, but there was some interesting discussion about ways to achieve the various refactorings (including one person who admitted to removing getters and setters by making the fields public!) It’s a shame there wasn’t a bit more time available.
Responsibility-driven Design with Mock Objects (Willem van den Ende & Marc Evers)
This was a quick introduction to the use of mock objects as a design tool (refreshingly a show of hands indicated that everyone present practiced TDD, and most used mocks), followed by a randori-style session (in Ruby, by popular vote) designing some classes for a simple adventure game.
As with the previous session, time constraints meant that we didn’t progress that far with the code, but there was a lot of discussion around various design decisions, which of course is the really valuable part of this kind of exercise. A lot of this was kicked off by Steve Freeman (co-inventor of mock objects, and co-author of the excellent Mock Roles, not Objects, where the proper use of mocks is explained), who piped up when someone suggested moving when there was some debate about the correct name for a method. From what I can remember, his comment was something along the lines of “No! Getting the right names for things is the whole point – if you aren’t going to do that, you might as well not bother!” I was reminded of the quote from Phil Karlton: “There are only two hard problems in Computer Science: cache invalidation and naming things.”
The main thing I took away from this session was some confirmation that the way I currently try to do TDD with mocks is fairly close to what seems to be considered good practice. Interestingly the number of people who agreed that the techniques shown were similar to how they currently used mocks was a fraction of the number that had earlier identified themselves as mock users, but unfortunately there wasn’t time to find out how their approaches differed.
My Defining Moments (Steve Freeman)
This was similar in a way to Ade’s, but instead of everyone talking for 90 seconds about their personal practices, a dozen or so volunteers talked for up to five minutes about a ‘breakthrough experience’ where they’ve learned something important, and how that breakthrough happened. Here are some of the ones I noted down (apologies if I’ve misrepresented anyone, but I only wrote down a few words for each and I may have forgotten the details):
Steve himself talked about when he was at DEC, where ‘everything just worked’. He described the best sysadmins he’d ever seen, who would, unasked, perform ‘random acts of helpfulness’. The main lesson he learnt from this was that despite the mediocrity found in most organisations, it was possible to be that good if you had the right people.
Micah described how some ways of working when he joined ObjectMentor hadn’t felt quite right to him, and his realisation that in the end you can’t impose one person’s standards on another: we all have to develop our own which we’re comfortable with.
Ade talked about his first project at ThoughtWorks. He described how his boss had shouted at him in a client meeting for describing himself as “just a developer”. His main point though was about working with a team of developers from Dixons, whose sole Java experience was a two-week course from Dan North. Obviously the lack of experience wasn’t ideal, but the fact that they’d learnt everything they knew from Dan meant that they only knew the right way to do things. For example if you suggested to them that something was too simple to need a test, they’d say “No, you have to start with a test!”
Willem van den Ende described an internship spent refactoring a hideous, bug-ridden, copy-and-pasted mudball of GUI code, which contained 40,000 lines of code and which no-one dared touch. In four months, by slowly removing duplication and cleaning up the code, he reduced it to a tenth of the size. He also found that he fixed most of the bugs without really trying, as a side-effect of removing duplication. The original code had taken two people three months to write.
Gojko Adzic talked about a project for the National Grid, where a graphical map view they’d added at the end of the project was by far the most popular feature of the software, despite the fact that the customer hadn’t asked for it. He highlighted the discrepancy between this and the common agile view that says you should only work on features (user stories) that the customer has explicitly asked for. My take on this would be that it’s part of the developers’ job to propose new or alternative solutions to the customer, but generally you should still get their agreement.
Finally John Daniels talked about a ‘lightbulb moment’ when moving from ADA to Smalltalk, where he suddenly understood what OO was really about. He said it was 20 years before he saw another language with a development environment as good as the Smalltalk one (something I’ve heard from others too).
I didn’t put my name down to talk, but for the record my defining moment would have actually have been a couple of events which have influenced my understanding and practice of TDD. From my initial one-test-per-method attempts at unit testing, reading about TestDox and RSpec introduced me to the idea of tests as specification. Then there were a couple of sessions from XPDay06, especially Are your tests really driving your development, which made me realise that my tests still weren’t expressing intent as well as they could have done. Finally the aforementioned Mock Roles, not Objects showed me the right way to use mocks and stubs.
Test-driven Development of Asynchronous Systems (Nat Pryce)
I’d already read the notes from this presentation, which Nat originally gave at XPDay08, but seeing the talk in person made it much clearer. I don’t think there’s much I can add to the notes.
General observations
Firstly, it was great to spend a day with a hundred-odd people who obviously cared about their work (not just their career) as software developers. The other thing that struck me was that, despite this not being explicitly an Agile or XP conference, it seemed to be taken for granted that practices like TDD and refactoring were basic necessities, not optional extras.
More randomly, there were far more non-Apple laptops in evidence than you would see at a Ruby conference or a Barcamp, presumably because a lot of delegates work for large companies and brought their work laptop. That said, most of the ones I saw seemed to be running Linux rather than Windows, but I wasn’t keeping count. More Java and .NET people too, although a fair proportion working in Ruby and other languages. On the phone front though, I don’t think I’ve ever seen so many iPhones in the same room! It seemed like every other person had one (even Ade, who was also showing off his Android phone, a Christmas present from his employer).
finally, a huge thank you to Jason Gorman and everyone else involved in organising the day, and to the BBC for hosting it.








 Traditional approaches to motivation tend to fall into one of two camps: the carrot (“do this and you’ll be rewarded”) or the stick (“do this or you’ll suffer the consequences”).
Traditional approaches to motivation tend to fall into one of two camps: the carrot (“do this and you’ll be rewarded”) or the stick (“do this or you’ll suffer the consequences”).{kind=link}