Well I successfully made it into the office on Monday and Tuesday, for the first two full days since March 2020. I remembered how to get there, I eventually found the old lock I’d left in the bike shed, and I forgot neither my laptop nor its power supply (although a 15″ Macbook is a bit less wieldy than the 13″ one I had two years ago, especially as I had panniers then and only a rucksack now). What I did forget though, at least on Monday, was my pass card. Particularly annoying given that security on my building has been tightened up even more, so I couldn’t even escape without someone letting me out. Also, thanks to some bizarre design decision, the toilets are outside a door that needs a card to get back in.
The office itself has been “upgraded” in the intervening time, so now instead of having our own desks where we can leave whatever possessions we see fit, it’s now first come, first served for any of a whole roomful of identical sterile desks, all lined up in neat rows, with stupidly wide monitors that block your view of whoever’s on the other side. Anyway, it was a nice change to see people, and at least I got a few games of table football in.
A surprisingly successful week on the running front, starting with the second of the Ipswich Summer Series 5k races in Christchurch Park. These seem to be getting less and less popular (probably thanks to a combination of the price creeping up and them no longer handing out bottles of wine as prizes), but I’d already paid for all four in one go, and with only 50 entrants I finished in a frankly ridiculous fifth place, picking up another age group trophy.
Then we had the last of the Friday 5 [mile] races, and despite it being on a fairly flat course at Great Bentley, and not too hot for once, I didn’t feel particularly optimistic. I was quite surprised, then, to still see a 33 on the clock as I turned the last corner to the finish line, and just about managed to sprint to a 33:59, which I then realised was a PB. Maybe I’m not quite getting irredeemably old and slow quite yet!
For some reason I then decided not to take it easy at parkrun, and managed a half-reasonable time, then ignored my original intention to skip today’s planned 13 slow miles, instead accidentally extending it to 18 (well mostly accidentally – some of that was a slight detour at the far end to a pub to refuel with a pint and some crisps). The main purpose was to get this month’s hollow tree photo – it’s an excellent tree that you can actually climb up the inside of, but that doesn’t really come across in the picture.
An idiot in a treeThis is how the elite athletes refuel mid-run, right?
Nearly forgot to post something this week. It feels stubbornly like a Saturday for some reason, which doesn’t bode well for me remembering that tomorrow I’m actually supposed to be going into the office for the first time in ages. It’s not that I’ve particularly avoided it up to now, but I’ve got into such a routine that it doesn’t usually cross my mind that I could go in until I’ve already made a coffee and started work. Anyway, my boss’s boss is in the country at the moment and in our office tomorrow (and Tuesday I think), so it’s probably a good idea for us to actually be there to meet him.
I’m not really sure much has happened since last time. I spent a couple of hours working out how to make Chartkick.js play nicely with Phoenix LiveView, and because I was feeling public-spirited and there wasn’t much detail around of how to do it (I think it’s one of those things that’s just simple enough that if you look on forums you see people asking, being given a hint then coming back saying “thanks, that made sense” without explaining exactly what they did) I decided to write it up.
Other than that, I think everything’s just running. We’ve got a trail of giant painted owls in Ipswich at the moment, so I went out to run round them on Wednesday. I missed a few, and still managed to go a couple of miles further than the planned 10. Then Stowmarket Friday 5 (much less roasting this week, but ended up slower than it felt), parkrun yesterday, and a nice chatty 14 mile trail run today on the Stour Valley Path, including a few wrong turns and a stop for an ice cream and a little paddle in the river. My Garmin is now recommending 3.5 days’ rest, which seems a bit excessive (especially as I have another 5k race on Tuesday).
I was converting some “old-fashioned” Phoenix code to a LiveView today, and got stuck for a while trying to get a Chartkick graph to render properly. I found various hints online about how to do it, and I assumed it was a case of phx-update="ignore" and some kind of Javascript hooks, but it took a bit of time to figure out the details. I thought I’d be helpful and write up an example, as it turns out it’s not that hard.
First let’s create the application. I skipped Ecto because we don’t need a database for this example.
So far, so good. Time to try it with a live view! Replace the root route in lib/my_app_web/router.ex with live "/", PageLive, and create the module in lib/my_app_web/live/page_live.ex, rendering exactly the same html as we had before:
defmodule MyAppWeb.PageLive do
use MyAppWeb, :live_view
@impl true
def render(assigns) do
~H"""
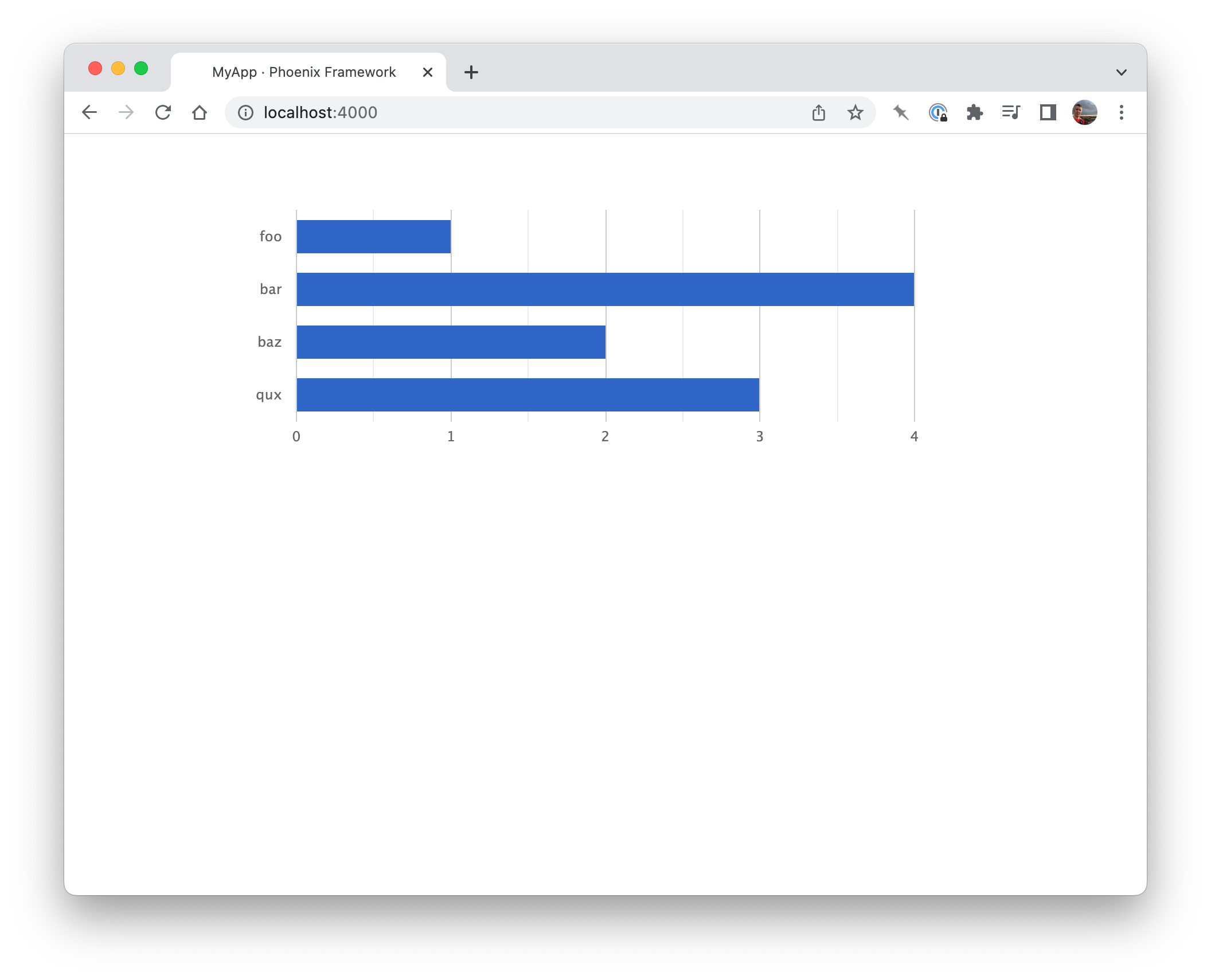
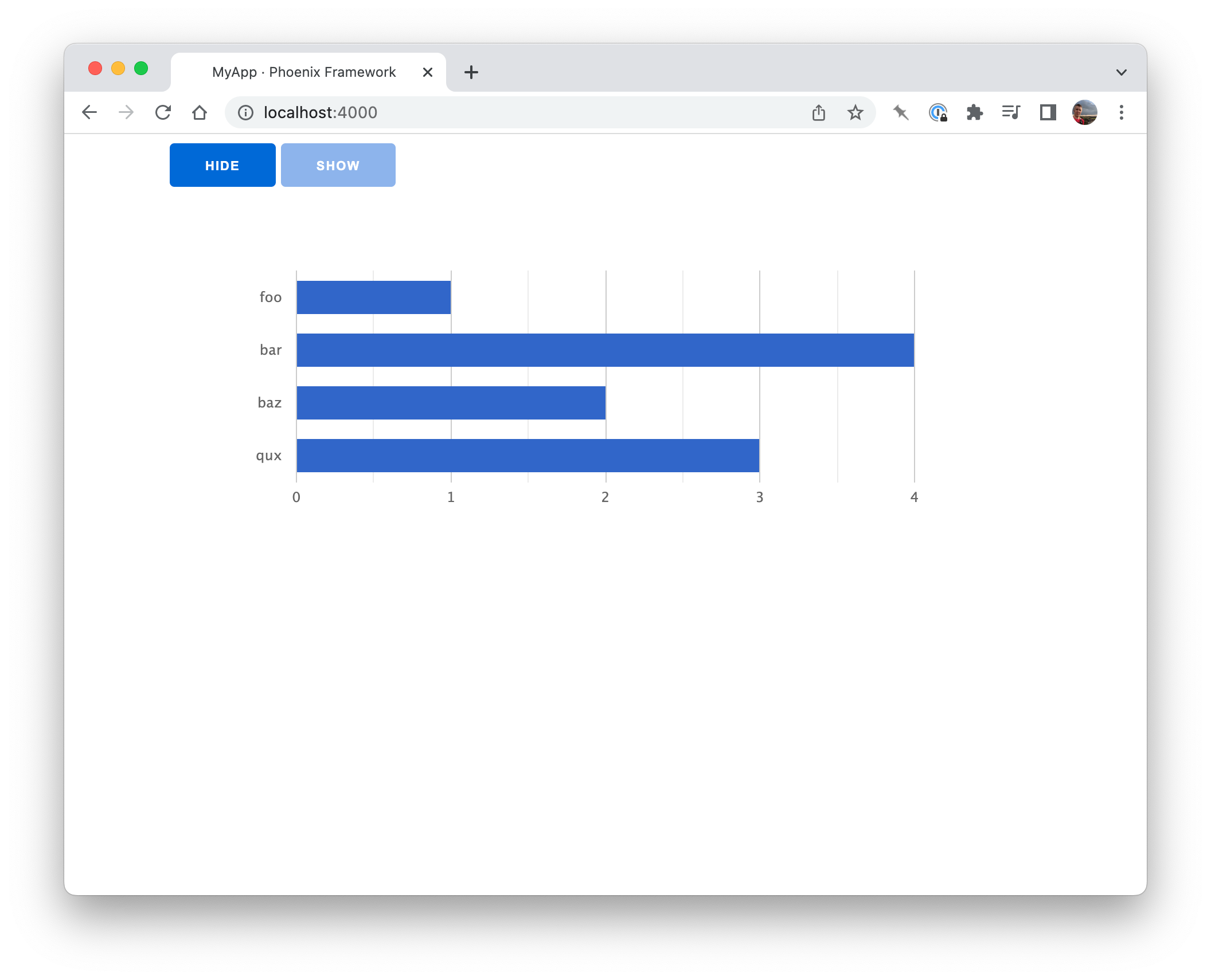
<%= "{foo: 1, bar: 4, baz: 2, qux: 3}"
|> Chartkick.bar_chart()
|> Phoenix.HTML.raw() %>
"""
end
end
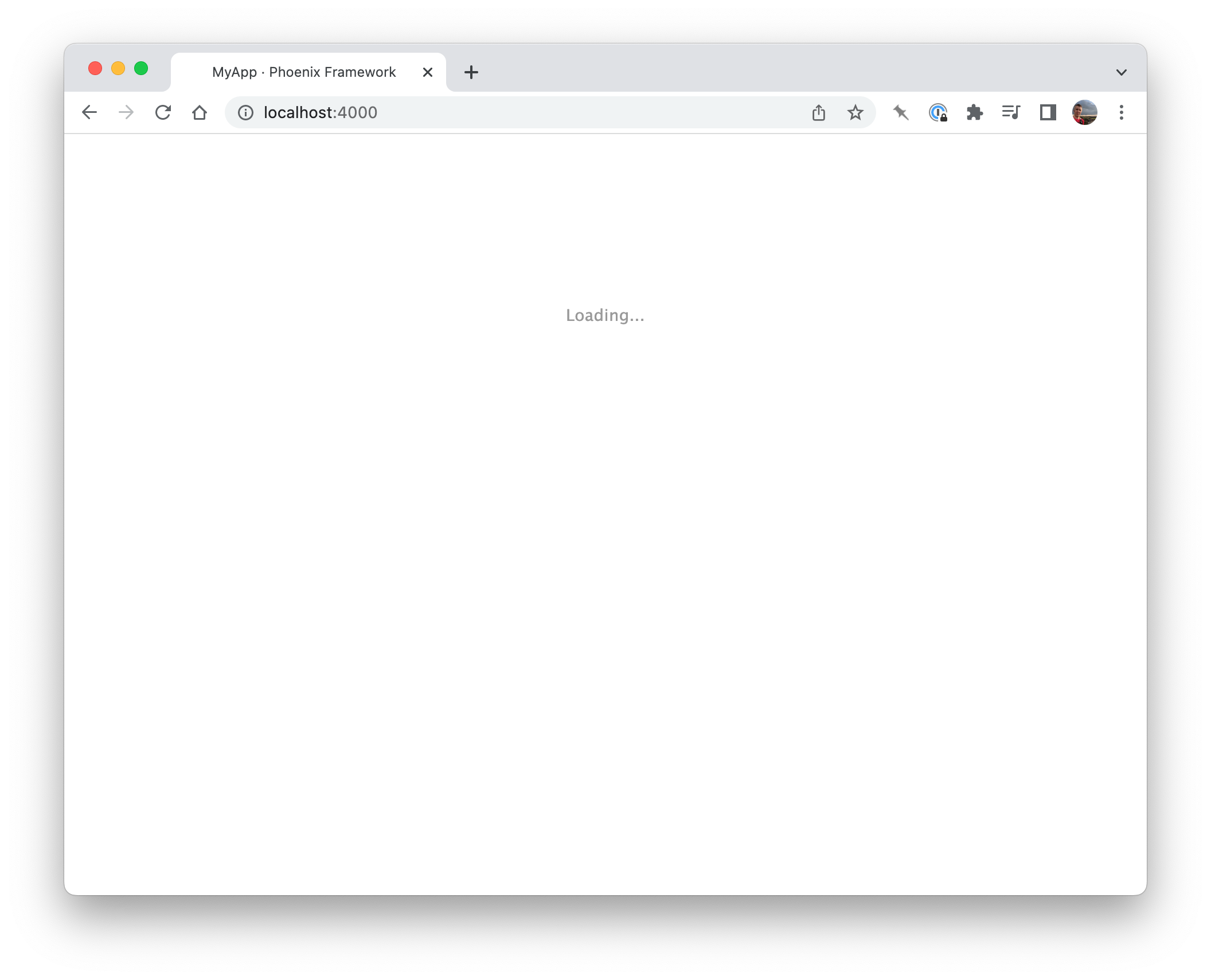
When this renders, we see the chart flash up briefly, then … hmm.
Perpetually loading
The reason we see the chart appear then disappear is that LiveView renders the page twice when it’s loaded – once statically, for search engines etc, then a second time, when it swaps in its dynamic Dom. Here are the elements that Chartkick initially creates (a placeholder div and a bit of javascript that will call the library and swap in the generated graph):
<div id="b5b7b558-1220-4546-a3e8-15e2e607b312" style="...">
Loading...
</div>
<script type="text/javascript">
new Chartkick.BarChart(
'b5b7b558-1220-4546-a3e8-15e2e607b312',
{foo: 1, bar: 4, baz: 2, qux: 3}, {});
</script>
The problem is that a script tag inserted dynamically into the Dom, unlike one in the original page source, doesn’t get executed. There’s also a potential issue with LiveView and Chartkick both trying to manipulate the same elements, leading to unpredictable behaviour when the page data is updated. We can address the latter issue by telling LiveView to ignore the chart when updating the page:
defmodule MyAppWeb.PageLive do
use MyAppWeb, :live_view
@impl true
def render(assigns) do
~H"""
<div id="chart" phx-update="ignore">
<%= "{foo: 1, bar: 4, baz: 2, qux: 3}"
|> Chartkick.bar_chart()
|> Phoenix.HTML.raw() %>
</div>
"""
end
end
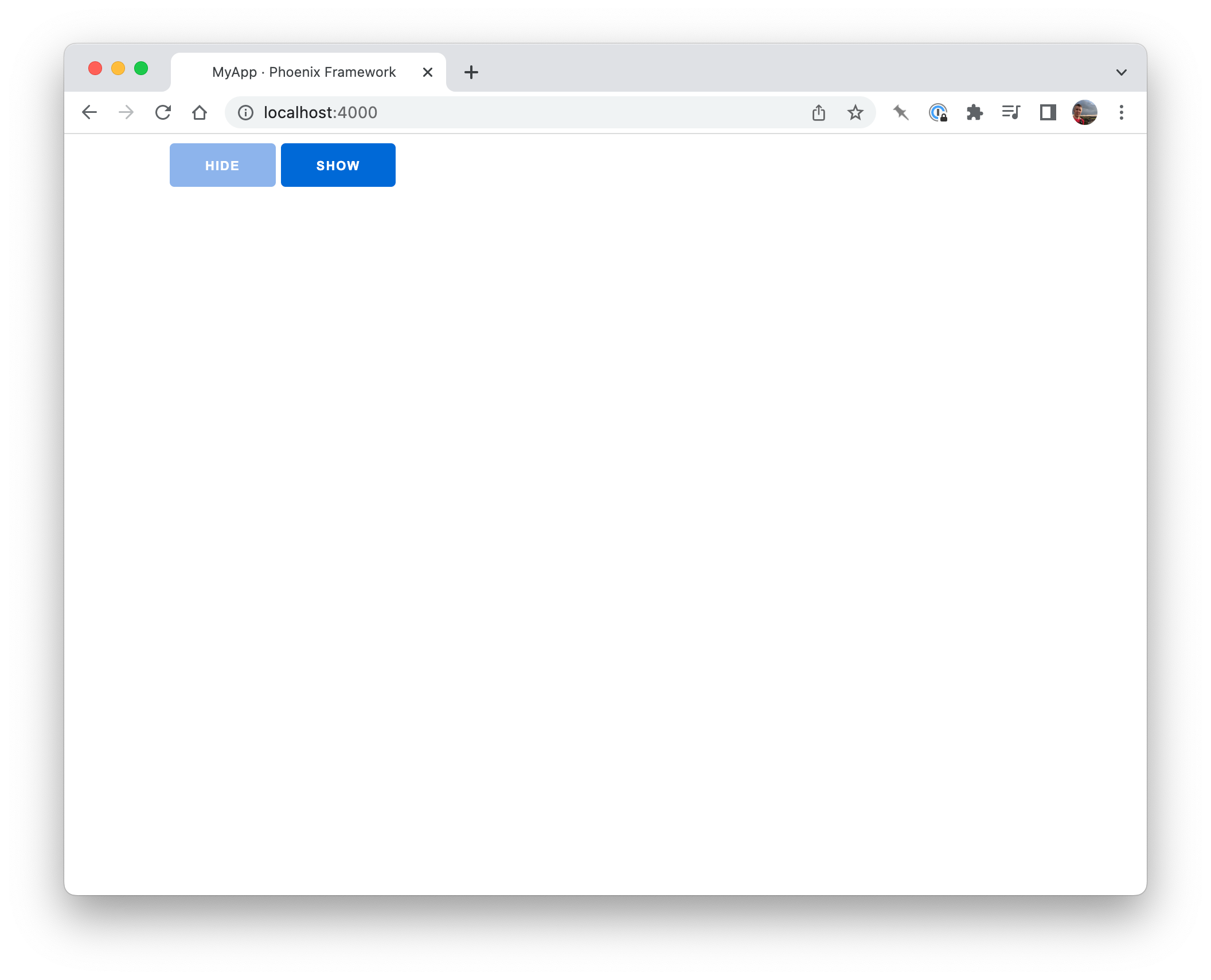
This actually works in our simple case, but what if the chart wasn’t always shown, or was part of a component that was live patched in? As the simplest possible illustration of this, let’s add some show/hide buttons and only render the element when we toggle @show to true:
defmodule MyAppWeb.PageLive do
use MyAppWeb, :live_view
@impl true
def mount(_params, _session, socket) do
{:ok, assign(socket, show: false)}
end
@impl true
def render(assigns) do
~H"""
<input type="button" phx-click="hide" value="Hide"
disabled={not @show} />
<input type="button" phx-click="show" value="Show"
disabled={@show} />
<%= if @show do %>
<div id="chart" phx-update="ignore">
<%= "{foo: 1, bar: 4, baz: 2, qux: 3}"
|> Chartkick.bar_chart()
|> Phoenix.HTML.raw() %>
</div>
<% end %>
"""
end
@impl true
def handle_event("hide", _params, socket) do
{:noreply, assign(socket, show: false)}
end
def handle_event("show", _params, socket) do
{:noreply, assign(socket, show: true)}
end
end
Initially the chart isn’t there, as expected:
Hidden …
But when we click “show”, we’re back to our perpetual loading indicator:
… and still kind of hidden
We need a way of triggering the Chartkick script when the view’s updated, and that’s where hooks come in. First define a hook in assets/js/app.js (I’m not entirely sure this is the best way of running the javascript, but it works!):
let Hooks = {
RenderChart: {
mounted() {
console.log("RenderChart")
console.log(this.el)
eval(this.el.getElementsByTagName("script")[0].innerHTML)
}
}
}
let liveSocket = new LiveSocket("/live", Socket,
{hooks: Hooks, params: {_csrf_token: csrfToken}})
There are other hooks as well as mounted – If we were dynamically updating the chart element itself we’d probably want to also execute the script on updated, for example.
And that’s it! The code’s here, and I hope it helps someone avoid a bit of head scratching.
This week’s main news is that Shadow cat has gone missing again. She didn’t turn up for any food on Wednesday, and I haven’t seen her since. She did disappear for a week a year ago, and turned out to have been hiding in my garage the whole time, but I’ve checked several times and she’s definitely not there this time. Still holding out hope that she might reappear again, but obvious the longer she’s missing the less likely it gets.
I put together a cryptic crossword for the first time in a while, and people seemed to largely enjoy it (the kind of people that have any interest in such things anyway), so I should probably do this more often. This one had a theme, which I usually seem to end up doing – you’d think it would be easier without, but it feels a bit weird for some reason.
I spent Monday afternoon grappling with a failing build caused by race conditions as some tests tore down database sessions after doing things which published messages to a queue, which caused things listening to those messages to terminate unexpectedly. There’s probably a lesson there about decoupling unit tests from the database, but in the meantime I tried all sorts of tweaks without any success. Then just after I’d given up for the day José Valim retweeted a tweet from German Velasco linking to his blog post about how Wojtek Mach had fixed a similar issue in LiveView. It wasn’t exactly the same situation as I had, but it was enough of a nudge in the right direction for me to finally fix the issue the next morning.
I did a quick TDD demo for some colleagues. It’s always hard to pitch this kind of thing so it’s neither too simplistic nor so complex as to be impenetrable or boring – this time I prepared a simple to-do web app, then test-drove a made-up feature involving a button which popped up a random item out of all those with the highest priority which weren’t yet marked as done. This meant I could throw in a bit of UI-based acceptance testing, then drive the domain layer with unit tests, including injecting the “random” algorithm to make the tests repeatable. Seemed to go OK, but it’s always hard to tell with these things. As usual, my main aim was to at least show people what a short “red-green-refactor” loop actually looks like, to dispel any misconceptions that TDD means “write all the acceptance tests to match the spec, then keep coding until they all pass”.
I marked Friday’s heatwave by running the Bury Friday 5. Not altogether the most pleasant experience, especially on top of a 40 minute delay getting there thanks to the A14 being closed because apparently it had melted. My slowest time of the series so far, but it turns out each of them has been slower than the last. Surely I can buck that trend at Stowmarket next week?
I failed to finish the hedge cutting that I started last weekend, blaming a combination of heat and lack of brown bin space (although it was mostly laziness), but I did at least spend a bit of time trying to pull up of cut down the worst of the brambles in what I’m stubbornly referring to as my “wildlife lawn”.
I encountered this chap on my long run today. Fortunately he seemed quite chilled and didn’t decide to charge at me, but just being stared at as I passed through his field was a little unnerving.
The fox has continued to hang around a fair bit, and I’m starting to think it is the same one after all.
A fox …
On Wednesday I finally got round to replacing the rat-chewed rubber seal between the sink waste pipe and the drain. But not before the rat made an escape through the gap under the open dishwasher, and spent Tuesday afternoon alternately hiding under things and chasing/being chased by the cats (I’m not really sure who had the upper hand). I had to take the (fitted) dishwasher out to get to the pipe, which was a pain, but at least when I put it back I managed to do a better job of lining it up than when I originally fitted it, so after five years the door’s finally no longer wonky!
… and a rat
A fairly uneventful running week, apart from a warm Framlingham Friday 5, and some mild embarassment at Tuesday’s club session involving losing the rest of the group, assuming they’d finished, heading back to the sports centre where we meet, then discovering that they’d actually just gone round the corner for a time trial. At least there were three of us, so I don’t have to shoulder all the blame!
My Buffy rewatch has now gone past S5E16, The Body – a strong candidate for the most emotionally battering 40 minutes of TV ever made. And because I’ve been listening to the Buffering podcast at a much-accelerated rate compared to their original release schedule, it feels like they’re in a whirlwind of coping with that episode, the beginning of lockdown, Black Lives Matter and various accusations against Joss Whedon.
I’ve been waiting for the final series of Brooklyn Nine-Nine to appear in the UK, thinking I might reactivate my Netflix account for a month to watch it when it arrived. I just discovered that (a) it’s moved to E4, and (b) as far as I can tell they’ve already removed the first few episodes from All 4. Harumph.
Today I actually managed to do a bit of gardening, strimming down the weeds in the driveway and making a start on cutting the hedges (I’d been putting it off mainly due to laziness, but also because I didn’t want to accidentally disturb any nesting birds. I did find an old nest, but fortunately nothing current). To be honest, this is still only a small subset of the bare minimum that needs doing, but at least it’s a start!
Well that’s the four day weekend pretty much over, and I still didn’t manage to summon up enough enthusiasm to cut my hedges (or hack down the weeds in the driveway, or any of the myriad other jobs that need doing). And because of the weird Thursday/Friday nonsense, we now get tipped straight back into a full week of work! Incidentally, can anyone [he writes in the pretence that more than one or two people are actually reading this] explain why the Jubilee celebrations were in the year that’s 70 years after the accession (which happened in January), but around the date of the coronation (which happened in 1953)? I guess it’s just about getting decent weather.
As you would expect, I largely paid no notice at all to the various celebrations and the like, although I did go to what was technically a jubilee garden party on Saturday (but was really just a bunch of friends drinking beer in someone’s garden). I also dug out some clippings of when seven-year-old me won a local radio competition for the silver jubilee. I didn’t look particularly happy about it, or more likely I just hated having my photo taken.
Fame at last (1977)
On Friday I ran in the long-delayed Run for A Rose 10k, on the flat but windy (and not terribly exciting) RAF Woodbridge runway. This was a charity event in memory of Angela Rose (hence the capitalisation of the name), a friend and local runner who died of cancer at a tragically young age, and was originally supposed to happen in early 2020. Ironically, it was originally postponed because of Storm Dennis, but that pushed it into the void of 2020–21. It was a shame it hadn’t been publicised a bit more, as it felt a bit sparse (I finished in 44 minutes something, and the people in front of and behind me were on 43 something and 45 something respectively. Ozzy, who won it, was miles clear of second place).
In rat-up-a-drainpipe news, I noticed a bit of a smell returning to the kitchen today, and discovered that the tea-towel I’d wedged in the pipe gap has mysteriously vanished. Not sure whether it was removed by reprobate rodents or just got washed away, but hopefully it hasn’t caused a blockage elsewhere (I guess I should poke around under the inspection cover and try to find it).
My new coffee grinder, to complement my new espresso machine, unexpectedly arrived earlier in the week. I say unexpectedly because the manufacturer’s website that orders placed when mine was would be delivered in July (which had just changed from June while I was procrastinating). Not sure why they’d say that then ship it out in May, but I’m not complaining.
I chose today’s run route to go through a massive local field of poppies – apparently they’re there every year, but this year will be the last because the field is about to be turned into a housing estate. Progress, eh?
Poppies
Finally, I found a fox sleeping in my garden again. I don’t think it’s the same one that has visited on and off for the past few years, or if it is it’s got a lot more nervous all of a sudden (apart from the whole casually sleeping in people’s gardens thing).
No more sightings of my under-sink rat lately, but I did end up blocking the hole he was coming up through (incidentally, I’m not sure why I tend to assume any animals I encounter are male). Not because I’ve got anything against the rat – I quite like the rat – but because it turns out having an open gap under your sink that leads out to the drains means that sometimes unpleasant smells find their way into the kitchen. Who knew? I need to get a replacement for the rubber pipe coupling that’s been chewed through, but for now I’ve just stuffed it up with an old tea towel.
I finally took the plunge this week and ordered the fancy new espresso machine I’d been drooling over on the internet for ages, along with a couple of extra accoutrements. I’m also upgrading my grinder, but there’s a bit of a waiting list for that so I’m stuck with the old one for now. Still, after a bit of practice I feel like I’m reliably turning out decent coffee. Which I sometimes did with the old lever machine, but it was always a bit of a lottery with so many variables. I was expecting to take a while to learn to froth milk with the more powerful steam wand, but surprised myself by making a pretty decent flat white the first time I tried it. To be honest it felt a bit odd spending so much money on a luxury item when half the country is struggling to make ends meet, but I don’t treat myself often, and I sent some money to the Trussel Trust to assuage a bit of my middle class guilt. Plus there’s the fact that I didn’t vote for the Tories, of course.
Old and new
Thursday got off to a good start when I dropped my phone in the loo. I’d put it on the cistern, and as I flushed it slid off. It would probably have been fine because the toilet lid was in the process of closing, but I instinctively tried to catch it to avoid it hitting the tiled floor, and after a brief amount of half-awake fumbling heard a splash as it bounced through the now-tiny gap between the almost fully-down seat and the bowl. Soft-close seats have their drawbacks, I guess. Fortunately it didn’t immediately die, and after leaving it in a 40° oven for a few hours the only remaining issue was condensation in the camera lens. Since then I’ve been leaving it in a zip-lock bag with some silica gel when I got a chance, and it seems more or less back to normal. I’m glad I’m not going to have to put up with all my photos from now on having a cheesy soft-focus dream effect.
Running-wise, the Week of Doom is finally over, having completed the Ipswich Summer 5k Series opener (Tuesday) and Sudbury Friday 5 (Friday, duh, but miles not km) hot on the heels of last week’s Kirton Friday 5 and the Stephen Williams 10k on Sunday. I even managed a half-decent parkrun yesterday, but I’m finally having a proper rest day today (also it’s raining). Somewhat amusingly, thanks to a lot of speedy old people not being there on Tuesday (turnout was sparse in general – I think they may be charging a bit much this year for what’s basically a parkrun with chip timing and jaffa cakes), I ended up winning my age category!
Never had one of these before!
I finally finished reading The Ragged Trousered Philanthropists. It’s an interesting view of the kind of low-wage, zero contract, high wealth gap, corruptly governed economy that was keeping working people in poverty a century ago (but which they kept voting to perpetuate). Or it might have been Jacob Rees-Mogg’s manifesto, I’m not sure. It’s an extremely long book though, which is less obvious when you start reading something on a Kindle rather than in physical form.
Still suffering the lingering dregs of a cold/novid, but mostly limited to my trademark annoying cough now. Annoying to me, but probably more annoying to others, although I’m in people’s earshot much less often than in the olden times.
I was on a call at work this week with a group of people who’d volunteered to take part in an agile mentoring programme. A good initiative (particularly as it seems to be a grass-roots thing, rather than something pushed by TPTB), but I was a bit sad to find myself the sole practicing software developer among a sea of scrum masters, product owners and agile coaches. It remains to be seen whether anyone will pick me as a mentor (I claimed the Manifesto for Half-Arsed Agile Software Development as one of my achievements in my profile).
A busier week of running this week, with club training on Tuesday, a 10k social trail run to the pub (but starting and finishing a seven mile cycle away) on Wednesday, then the long-awaited return of the Friday 5 [mile] series (you can tell how keen I was to enter by my bib number!), then parkrun, and finally the Stephen Williams 10k on Sunday (which wasn’t quite as hot as last year, but still pretty toasty). Now a whole day off before the first Summer Series 5k race on Tuesday, then the second Friday 5 is on … well, you can probably guess which day it’s on.
Kirton Friday 5
I still seem to be getting ratty visitors under my kitchen units. The other day the cats were getting excited so I pulled the kick board off to see one dive down the pipe, then pop back up and end up sitting there with his head down and his tail sticking out. I shut it up again and shortly afterwards heard a loud squeaking and some kind of murine contretemps, so I assume he encountered a colleague on its way up. I should probably block the gap up, but I kind of want to get a photo first and they haven’t done any actual damage yet.
Jane had contacted a few potential buyers for her Mini, and today Redwood Classics came to take a look, offered her a better price than the previous two people, and ended up taking it away and leaving a pile of actual cash (remember that?) in its place. They actually seemed more interested in my 1275GT, and offered me nearly twice what I paid for it, but I’m still minded to hang onto it for now, and at some point get it back on the road – maybe eventually with an electric conversion. They did give me £150 for an old engine I had lying around though, which was an unexpected bonus. They also know someone who might want the Spitfire, which I’m happy to sell if I get a reasonable offer.
I started to get a sore throat at the beginning of the week, followed by a cough, and wondered whether I’d finally ended my run of escaping the novel coronavirus. It seems it was probably just the boring old fashioned kind of coronavirus though, which has now progressed through streaming nose to more coughing (and if we’re back to traditional colds, will probably result in a lingering cough until I catch the next one). At least thanks to JP, I had a new word for it.
Think it’s time for a new phrase: “I’ve got Novid”. A quick and convenient way of saying “I don’t feel particularly well, bit of a cough, bit of a cold , but I’ve tested myself and no, I don’t have Covid”. (By the way I don’t have Novid, just that I keep meeting people who do).
On Thursday a few of us went to help finish the leftover beer from the weekend’s party, and sat in the garden with a takeaway curry. Nice that the weather’s starting to make outdoor gathering pleasant again – despite a couple of negative LFTs I’m not sure I’d have been popular turning up for an indoor do with a cough.
We’re supposed to start going into the office for a day or two a week again now (and I was due to go in on Thursday to help someone out with an interview), but I excused myself on the basis of germs. Should probably make an effort and go in soon, but it was very noticeable that when I got up at “going into the office” time then decided not to, I was able to start work a good hour or so early.
More racing at the weekend, with the confusingly-named Twilight 5k taking place on the waterfront on Saturday afternoon. This race was the scene of my PB in 2019, with a time that should have put me in the sub-20 wave, but as I appear to have slowed down a bit while waiting for it to finally take place again I estimated my time at 21 minutes which put me in the middle wave again. As it turned out I managed 21:28, which I’m happy enough with given I was still full of cold (and the weather was very much not cold). The local venue also lent itself to hitting the pub afterwards and walking home at closing time. Because we’re all proper athletes and stuff.
The number of half a beast
Today Jane came round to take some photos of her Mini 40, which has been sitting in my carport since she moved out in 2015 (and for several years prior to that), and which she’s finally thinking of selling. The plan was to shuffle the other cars around a bit and push it out, but it turned out that after pumping all the tyres up my 1275GT was the only one whose brakes were free enough to actually move anywhere. I did take the opportunity to wash off most of the moss that had been taking it over, so it looks properly yellow again. Also discovered a whole stash of mysteriously missing CDs in Jane’s mini, that must have been there for 13 years or so. I think one of them is still in the stereo though – hopefully the security code to switch it on is written down somewhere!
Hmm, another week, you say? Not sure where they’re all disappearing so fast, to be honest.
I went to a friend’s 60th birthday party on Saturday. I’m not really a party person – I hate the idea of trying to make small talk with strangers – but there were enough people there that I knew to allow me to mostly lurk in corners talking to them, and had a generally OK time. I was slightly surprised that out of what must have been a hundred-odd people there, it seemed like only four of us had cycled there, but I guess a lot of them had come from further afield (or close enough to walk).
Fortunately we were all kicked out of the venue at 10.30 (that was the plan – there wasn’t a riot or anything), so I wasn’t completely wrecked for the Woodbridge 10k today. I hadn’t run it since 2016, and had forgotten quite how hilly it is, and it also felt boiling hot, although I’m pretty sure the actual temperature was only in the mid-teens. A great atmosphere as always, with half the town apparently turning out to watch (I suspect the fact that the route passes multiple decent pubs helps).
My Buffy rewatch has now reached season four, which is where (a) they go to college, (b) they started filming in what at the time we called “widescreen”, but I guess now we just call “normal”, and (c) the DVD producers got me again with their horrible UX trick of switching from a menu where four episodes are laid out like this:
1
2
3
4
… to one where they’re laid out like this:
1
3
2
4
I’ve also almost caught up with the Buffering podcast to the point where it matches the episode I just watched. Those are from a few years ago (coincidentally I think in real time they’re about to finally reach the show finale), and I’m mainly interested in what happens when Joss Whedon’s me too fall from grace hits their timeline.
I had another go at getting the ADC for my weather station working after abandoning it for a while, and despite swapping in a different IC it still resolutely failed to read anything other than zero. I suspect it might be a software error (no doubt on my part), so I think I might have to temporarily switch from Nerves to a more traditional python image just to check that the hardware’s all wired up right.
That’s about it I think. Maybe I’ll do something interesting next week, but I’d advise against holding your breath (assuming anyone’s still reading at this point!)